
There has been a lot of press recently about misconfigured Amazon S3 buckets leaking confidential information. The root cause of this is that in the past S3 buckets have been incredibly easy to misconfigure. Sometimes buckets are made web accessible by anyone. Other times buckets are web restricted but can be accessed through Amazon S3 API by any authorised user.
Due to the nature and number of these breaches, Amazon have recently released their Trusted Advisor service for S3 for free to everyone to try to crack down on the problem. The challenge now is getting people to look at the new output and make changes based on the feedback. In the meantime, let’s have some fun kicking over S3 buckets to see what bounties fall out.
Finding S3 Buckets
S3 buckets are all reachable via a web interface, whether access is permitted or not. The URL format is:
http://<bucketname>.s3.amazonaws.com
– or –
http://s3.amazonaws.com/<bucketname>
The naming convention for S3 buckets can be summarised as follows:
- Bucket names must be at least 3 and no more than 63 characters long.
- Bucket names must be a series of one or more labels. Adjacent labels are separated by a single period (.). Bucket names can contain lowercase letters, numbers, and hyphens. Each label must start and end with a lowercase letter or a number.
- Bucket names must not be formatted as an IP address (for example, 192.168.5.4).
This means that there is a finite number of S3 buckets possible, even if this number is very, very large. In theory, with enough time and resources, you could kick every possible bucket URL to see if they exist. If you did so you would get one of the following HTTP response codes for each request:
- 404 – bucket not found (bucket does not exist)
- 403 – bucket found but access denied via the web(bucket does exist! Make a note of this)
- 200 – bucket found and accessible via the web!
By kicking every possible URL you can get a complete list of all buckets that exist. Anything web accessible, go have a look and see what you can find. Anything not web accessible, fear not, there’s still more we can do later via the S3 API.
Generating bucket names
As I mentioned before, if you did want to kick every possible S3 bucket name you could do it with enough time and resources. The number of possible buckets grows very quickly with the addition of each character added to the name’s length:
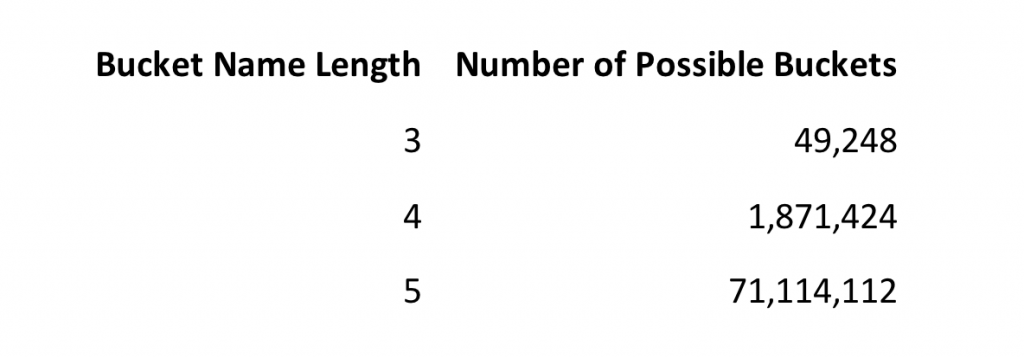
These numbers are for valid names only. After 5 chars in length things start to get a bit silly and we need to do something a little more clever. With my sysadmin hat on this is a basic approach for how I would name s3 buckets for the domain name example.com
- example.s3.amazonaws.com
- example.com.s3.amazonaws.com
- example-com.s3.amazonaws.com
- subdomain.example.com.s3.amazonaws.com
- subdomain-example-com.s3.amazonaws.com
- com.example.s3.amazonaws.com
- com-example.s3.amazonaws.com
- com.example.subdomain.s3.amazonaws.com
- com-example-subdomain.s3.amazonaws.com
- comexample.s3.amazonaws.com
- examplecom.s3.amazonaws.com
- subdomainexamplecom.s3.amazonaws.com
- comexamplesubdomain.s3.amazonaws.com
This is a nice starting point for generating a list of bucket names to brute force targeting a specific company. There are many more possibilities such as subdomain.subdomain.example.com and the other format variations for this, but I’ll stop that the list above for this article. I’d also consider the following:
- example<wordlist>
- example-<wordlist>
- example-<wordlist>1, 2, 3 etc.
- example-<wordlist>01, 02, 03 etc.
- <wordlist>example
- <wordlist>-example
- <wordlist>-example1, 2, 3 etc.
Using a wordlist for things like database, backups, archive, files, etc. SecLists is a great place to go for these wordlists.
Google Dorking
Google is another useful place to find bucket names but they appear very rarely. Here are some example dorks:
site:s3.amazonaws.com example
site:s3.amazonaws.com example.com
site:s3.amazonaws.com example-com
site:s3.amazonaws.com com.example
site:s3.amazonaws.com com-example
Using the S3 API
Using the S3 API is a chargeable action. The prices are very low but with millions of requests the charges add up. As you’ll be using your Amazon account if you use the S3 API you’ll be the one footing the bill.
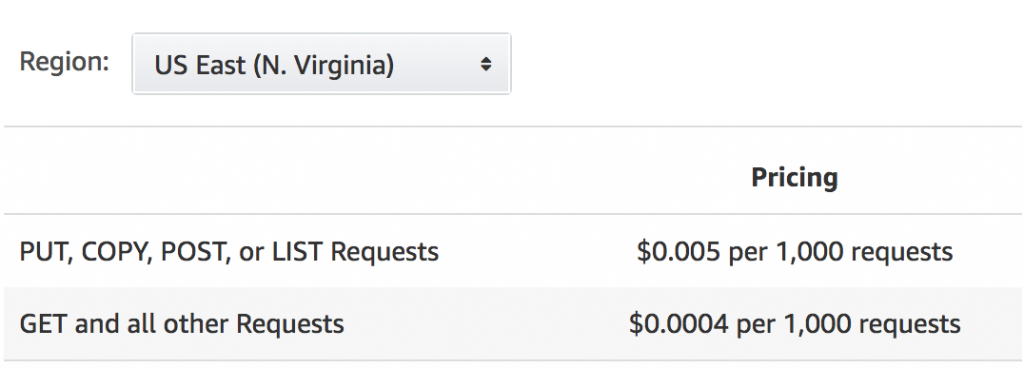
Because of that, always use the HTTP public interface instead of S3 API for doing large scale bucket URL kicking. Once you’ve finished that switch to the S3 API with your output for the next step.
As mentioned before, 403 and 200 requests mean a bucket exists. With this in mind it’s time to take the output from our web scraping and feed it into something that analyses at the S3 API instead of anonymous web requests.
A common misconfiguration with S3 buckets is to permit ‘Any Authenticated AWS User’ read, write, or read/write access to a bucket. Administrators previously misunderstood this as ‘Any authenticated user within my account’ but it actually means ‘Any authenticated user on any account’. We can use the API with our own valid AWS login to test for this by issuing a LIST request to the root of the bucket. If a response is returned then the next step is to try a GET request for an item listed in the output. The next step is then to try to create a new file. Perform a GET request for a rather random filename that shouldn’t exist, confirm it’s not found, then attempt to PUT a file into that location. If it works the bucket is probably completely open.
Automating the Process
To automate this process I’m working on a hard fork of Jordan Potti’s original AWSBucketDump. You can find bucketkicker here:
So far I’ve automated the HTTP elements of the process and created a very basic s3 bucket name generator. Next I’ll be adding an S3 API call element to further test 403 and 200 HTTP responses.
Leave a Reply